
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- PrestoDB
- kafka ui
- PostgreSQL
- Python
- SSL
- logstash
- Kafka
- kibana
- ui for kafka
- naverdevelopers
- kafka connect
- MariaDB
- elasticearch
- fluentd
- pyspark
- elasticsearch
- MongoDB
Archives
- Today
- Total
Dev_duri
Fluentd Web crawling 본문
현재 테스트 서버에 아래와 같은 데모 시나리오 테스트/개발 을 완료 하였습니다.

1. NAVER Developers를 활용하여 원하는 키워드의 뉴스를 Crawling 하도록 파이썬 코드를 구성하였습니다.
import requests
import json
import avro
from bs4 import BeautifulSoup
from fluent import sender
from datetime import datetime
sender.setup('myapp', host='fluent.host.ip', port=8888)
url = 'https://openapi.naver.com/v1/search/news.json?'
clientid = "ERgXUWS4ipcN34mBCk2D"
clientsecret = "PISIoaGK2t"
queryString = "query=" + "chatGPT" # 검색할 키워드
header = {
"X-Naver-Client-Id":clientid,
"X-Naver-Client-Secret":clientsecret
}
response = requests.get(url + queryString, headers=header)
data = response.json()
input_str = 'Tue, 21 Mar 2023 00:00:00 +0900'
current_date = datetime.now().strftime('%Y-%m-%d %H:%M:%S %z')
dtb = datetime.strptime(input_str, '%a, %d %b %Y %H:%M:%S %z')
dt = dtb.strftime('%Y-%m-%d %H:%M:%S %z')
for item in data['items']: # 기준이 되는 시간과 비교하여 해당되는 것만 표출
item_date = datetime.strptime(item['pubDate'], '%a, %d %b %Y %H:%M:%S %z').strftime('%Y-%m-%d %H:%M:%S %z')
if item_date < dt:
data['items'].remove(item)
elif item_date >= dt:
print( item['pubDate'])
else:
print("\n""null""\n")
req = requests.request('PUT','http://fluent.host.ip/tag',json=data)
print("\n","req = ",req.json) #json 형태로 크롤링한 자료 표출
2. 이후 Json 형식으로 데이터 표출 및 Fluentd를 활용하여 Elasticsearch에 데이터를 적제합니다.
-
Fluentd는 다양한 소스에서 로그를 수집해 중앙화할 수 있는 오픈소스 데이터 콜렉터입니다.
-
다양한 시스템에서 들어오는 여러 로그들을 fluentd 하나로 수집하고 파싱하고 포워딩할 수 있습니다.
-
Logstash에 비해 다수의 플러그인을 사용하면서도 복잡하지 않은 단순한 구조라는 장점이 있습니다.
-
If 문 형태인 Logstash에 비해 로그 분석 구조를 하고 있어서 상세한 분석은 불가능 하다는 단점이 있습니다.
<source>
@type http
port 8888
bind 0.0.0.0
</source>
<match tag>
@type elasticsearch
host elastic.search.host.ip
port 9200
index_name news
include_tag_key true
</match>
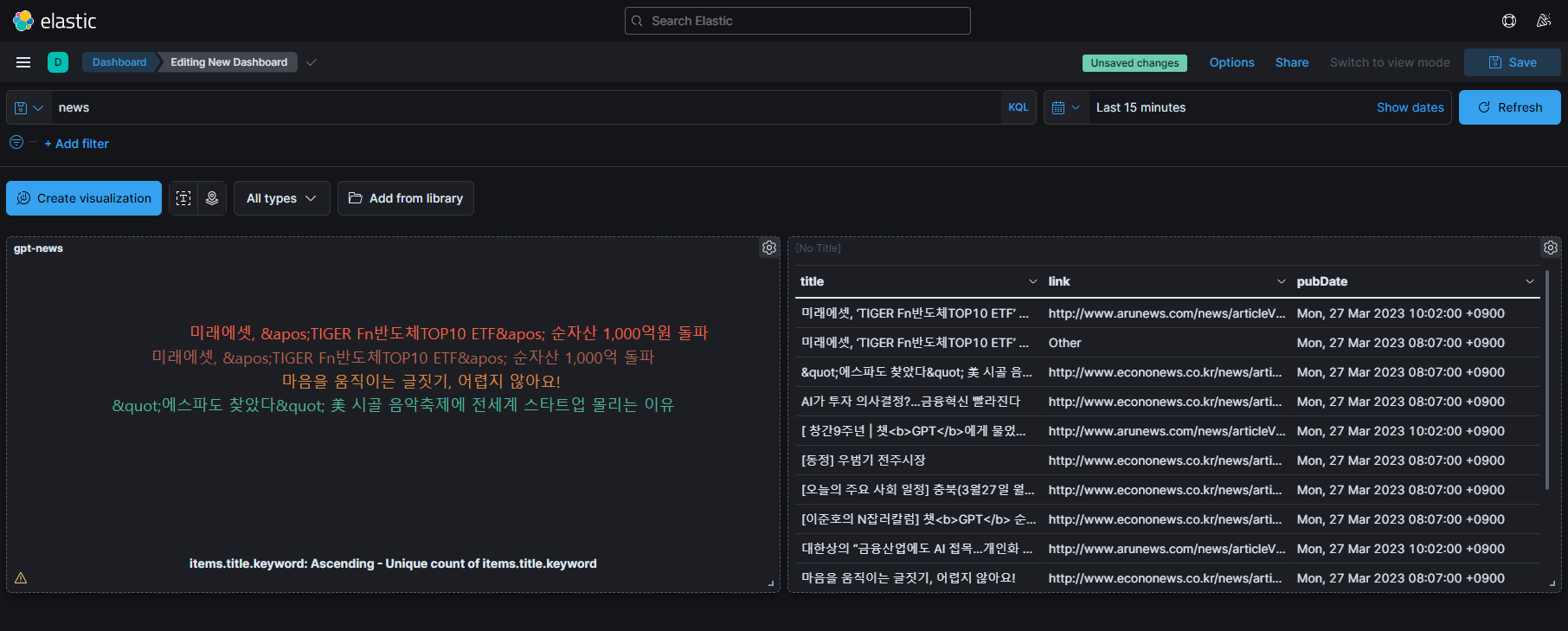
위 데이터는 Chat GPT를 키워드로 넣었을 때, 검색된 뉴스들을 Elasticsearch를 통해서 Kibana의 GUI 기능으로 띄운 화면입니다.
Kibana는 Tag Cloud를 포함한 여러 Metric 기능으로 데이터 시각화에 뛰어난 가시성과 편의성을 제공합니다.
'Elastic Stack' 카테고리의 다른 글
| EFK (ESB연계KAFKA) (0) | 2023.02.16 |
|---|---|
| EFK (RDB 연계) (0) | 2023.02.16 |
| ElasticSearch 관련 용어 정리 (1) | 2022.12.10 |
'Elastic Stack' Related Articles
more

