Kafka
Kafka Connect 개념
marcel
2025. 4. 10. 10:47
개념
Kafka Connect는 커넥터 플러그인을 사용하여 Kafka 브로커와 다른 시스템 간에 데이터를 스트리밍하기 위한 통합 컴포넌트이다.
Kafka Connect는 커넥터를 사용하여 데이터를 가져오거나 내보내기 위해 데이터베이스와 같은 외부 데이터 소스 또는 대상과 Kafka를 통합하기 위한 프레임워크를 제공합니다.
- 데이터소스 → Kafka Cluster 방향으로 데이터소스의 이벤트 스트림을 브로커에 저장하는 Connector를 Source Connector 라고 한다.
- Kafka Cluster → Target System 방향으로 토픽에 저장되는 이벤트 스트림을 타겟 시스템에 저장하는 Connector를 Sink Connector 라고 한다
구성

- Kafka Connect는 내부적으로 다음 3가지 컴포넌트들로 구성되어 있다.
1. Connector
데이터를 가져오거나 보내는 핵심 역할을 수행하는 컴포넌트
- JDBC Source/Sink Connector: DB ↔ Kafka
- Debezium CDC Connector: DB 변경 이벤트 → Kafka (CDC)
- Elasticsearch Sink: Kafka → Elasticsearch 저장
- MongoDB Source/Sink: Kafka ↔ MongoDB
2. Transform(s)
Kafka 토픽에 전송되기 전 or 받은 후의 데이터 구조 변환 또는 필터링 처리를 담당
간단한 데이터 정제 또는 필터 작업이 가능
- 필드 제거 / 추가
- 키/값 구조 변경
- 토픽 이름 동적으로 변경
3. Convertor
Kafka 내부에 저장될 때 사용되는 데이터 직렬화 형식 변환기
- JsonConverter: JSON 포맷
- AvroConverter: Apache Avro 포맷 (Schema Registry와 함께 사용)
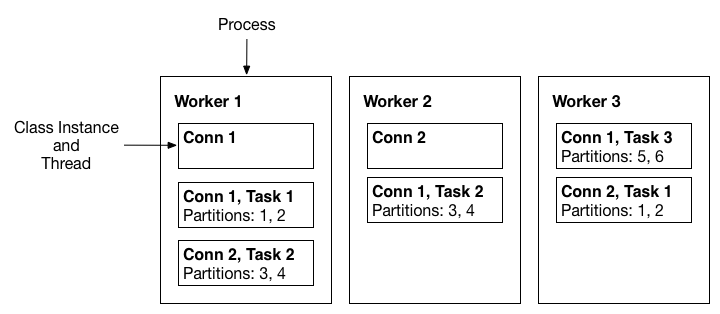
1. Worker
- Connect를 기동시키기 위한 Framework를 갖춘 JVM Process Model
- Connect Process를 Worker Process 라고 지칭한다.
- Connect는 서로 다른 여러 개의 Connect Instance(클래스) 들을 자신의 Framework 내부로 로딩하고 호출 / 수행 시킬 수 있다.
2. Task
- 커넥터가 일을 수행하는 단위
- Connect Instance의 실제 수행은 Thread 레벨로 수행되며 이를 Task 라고 한다.
- 병렬 Thread 수행이 가능할 경우 여러 개의 Task Thread들로 해당 Connector를 수행할 수 있다.
3. Connect
- 같은 Node에 “다른 Port“ 로 복수개 올릴 수 있음
- 1개의 노드에서 여러 개의 Worker Process들 또는 여러 개의 노드에서 여러 개의 Worker Process들로 Connect Cluster를 구성할 수 있다.
- Connect 유형은 Standalone과 Distributed Mode로 나뉜다.
- 단일 Worker Process로만 Connect Cluster 구성이 가능할 경우 Standalone Mode
- 여러 Worker Process 들로 구성이 가능할 경우 Distrubuted Mode
지원 가능한 커넥터 플러그인
- 다양한 DB 및 데이터소스들을 지원하며 각 데이터소스의 JDBC 플러그인은 해당 밴더사에서 무료, 혹은 유료로 지원하고 있다.
- Kafka의 개발사인 Confluent 에서 오픈소스, 커머셜 라이선스로 다양한 데이터소스에 대한 플러그인을 제공하고 있다.